Welcome to the fifth installment of the Learn to Build Better series. This multi-part series showcases the tools and techniques to rapidly build, test, and prototype energy-focused applications, analytics and use cases on the Awesense Platform, using the Energy Data Engine™ to process data, and TGI or APIs to access and visualize the data structured according to the Awesense Energy Data Model (EDM). This episode focuses on data science notebooks like Apache Zeppelin and Jupyter Notebook. To learn about web-based data science notebooks, check out episode nine of the Learn to Build Better series.
What are Data Science Notebooks, and why do we use them?
Data scientists use many tools to interpret and analyze data in various ways. Data science notebooks are one of the most essential tools in a data scientist’s arsenal regarding advanced data processing. Notebooks allow data scientists to write code, design custom applications (embedded analytics) and generate interesting and impactful visualizations of their data. They allow data scientists to interact with their code, change portions of it, and analyze where errors may arise. This allows for optimal customization while maintaining a robust structure throughout the code.
Notebooks are many times used to design more custom and niche applications, which may require more love and care than a typical method may allow for. This means that each notebook gets built from scratch or at least a simple template, and the data scientist can embed their personality and vision right into the code. This can then be used to share their results with team members and key decision-makers and to execute critical decision-making from the results that arise. Overall, data science notebooks allow for greater flexibility in building focused applications, leading to the best outcomes.
Because of their ease of use and increasing availability, many other groups of people are beginning to experiment with data science notebooks to achieve their data-driven goals. This includes people in roles such as business analysts, engineers, and any other role that requires someone to work with data.
Active Storytelling
Notebooks transparently outline the steps and code required to reach a conclusion; this allows for a story to be created using the data provided. This storytelling is a powerful way to connect the gap between our understanding of the world and the data we use to make decisions about it. Like most stories told by data, a certain genre or structure is put in place to guide it so we can make proper sense of it.
Step one involves defining a data set. This is important because it allows us to discover which data source we are using, preparing, and relying on to decide. Step two is the cleansing and preparation of that data, but no need to worry about that yet, the Awesense Energy Data Engine’s validation, editing and error eorrection (VEE) algorithms will take care of that part for you! Step three involves your creative side coming up with some models and schemas you think would be best suited for the data to tell that Cinderella story to your own Prince Charming (or a crucial decision-maker in this case)! Lastly, step four involves interpreting the results of the story you told. This is where you get to decide whether it’s a happy ending. By being able to parse through every line of the story you’ve written and see how the interactive interpretation leads to a natural conclusion, you can be sure that the glass slipper will fit.
Data science notebooks have recently received much attention because they help tell a story that matches the data and the user’s intention. Though many tools exist in this space, such as Deepnote, Polynote, Mode, Google Colab, and others, Jupyter Notebook and Apache Zeppelin are the two data science notebooking tools we will focus on below.

Jupyter Notebook
“Now that she’s back in the atmosphere, with drops of Jupiter in her hair… She acts like summer and walks like rain, reminds me that there’s a time to change…” – Drops of Jupiter, Train (2009)
With some beautiful song lyrics, we can’t imagine a better introduction to our most beloved notebooking tool, Jupyter Notebook. As a technology company, we spend a good portion of our free time romantically engaging with the future of electric vehicles and incredible data science tools, much of which serves to remind us that there is time to change. Jupyter Notebook (formerly iPython) is the most popular notebooking tool in use today. With support for almost 50 programming languages, including Python and R, there’s pretty much not a thing we can’t change about the old way we used to work with data.
Though limited in certain capacities, third-party tools are easy to integrate and use to achieve any desired result. We promise we’re not trying to advertise for Jupyter Notebook; we really like them!
Why We Love Jupyter as a Notebooking Tool
Jupyter notebooks integrate easily with open-source platforms used by many data enthusiasts, such as Github. GitHub’s gist allows for a clear, easy display and an easy-to-use interface for Jupyter notebooks viewing and reading. Jupyter notebooks operate through a basic IPython Kernel. This means it does not allow for switching programming languages between cells, but some third-party tools enable this functionality if needed.
Jupyter notebooks are JSON file types, meaning they easily store code as simple data structures and javascript. This means that users can access notebooks via their browser and even read and annotate them from Github’s gist.
Some spin-off features exist, such as Jupyter Lab (The Future); this means that there is a range of options for your preferences and what you plan on using Jupyter notebooks to do. This offers much flexibility in working with preferred data and formats, meaning anyone can use Jupyter notebooks to create what they have in mind.
Another reason we love working with Jupyter notebooks is because they can easily be turned into a standalone data application using frameworks like Voila or Panel. These frameworks and the whole world of embedded analytics are topics we’ll explore more in-depth in future articles in this series (stay tuned!).

Apache Zeppelin
Were you expecting Led Zeppelin lyrics to start us off? Not quite this time. If Jupyter notebooks take gold, Apache Zeppelin is always right behind, bagging silver on the podium. As the second most popular data science notebooking tool out there, Apache Zeppelin supports four primary languages, namely Scala (Spark Scala), Python (PySpark), R (SparkR), and SQL (SparkSQL).
Why We Love Apache Zeppelin as a Notebooking Tool
Apache Zeppelin has some incredible integrations features, specifically its in-built integration with Apache Spark. This feature allows users to pull from databases using a Java API. We love Apache Spark, an adjacent tool in Apache Zeppelin because it is a cluster computing system that supports Spark data frames and lazy executions. These are extremely useful while working with large time-series datasets or GIS data.
Not just that, though, Apache Zeppelin can be used for data ingestion, discovery, analytics and visualization, and collaboration to share your knowledge with a wider team. Apache Zeppelin even supports multi-user support and editing.
Though Apache Zeppelin can be controlled via Github, its display functionality makes it a tad bit harder to share notebooks as it often displays them as plain text files over the cloud. That said, with browser capabilities, this is not always an obstacle in the workplace.
A unique feature Apache Zeppelin offers is allowing users to use pre-built visualization widgets from the cell-produced data frames. This is more capable than even Jupyter notebooks, as most notebooking tools do not allow for this level of convenience.
The Fun Part- How We Notebook (With Examples!)
It’s never fun being left out, and that’s how many data scientists and engineering professionals feel when they see the expansive opportunities data science notebook tools offer. Because of that, we developed ways so that these data professionals can connect their preferred notebooks to the Awesense Platform and benefit from our Energy Data Model!
Examples, Examples, Examples!
Below are examples of how we use notebooking capabilities in Apache Zeppelin and Jupyter Notebook combined with the Awesense Platform.
Jupyter Notebook
We like to connect to the Awesense Platform from Jupyter notebook using two ways. First, use Jupyter SQL magic, and second, use the python PostgreSQL adapter module. Let’s start with SQL magic.

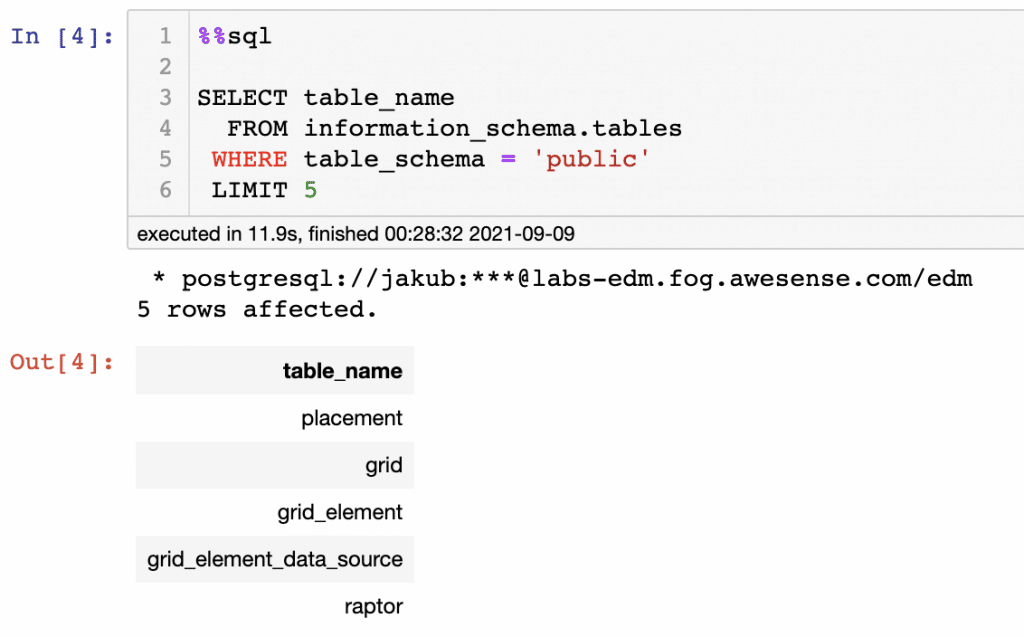
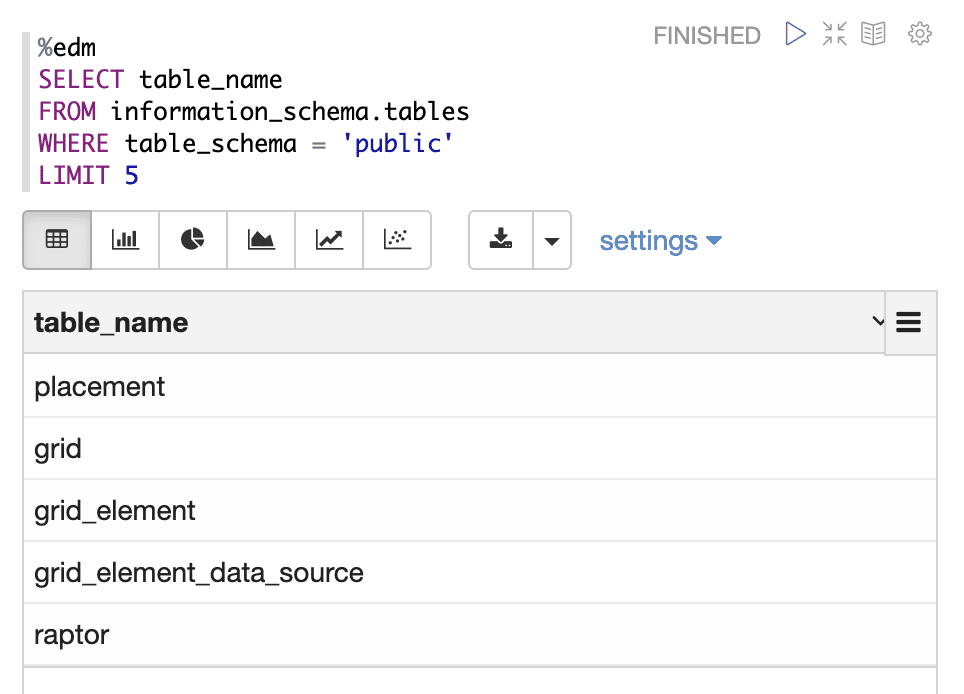
Above are two lines of code that are loading Jupyter’s SQL magic. This is all that it takes to connect to the Awesense Platform’s database’s Energy Data Model data layer. From here we can use SQL to access the Energy Data Model. A simple query can be seen below, displaying a subset of tables from the database.
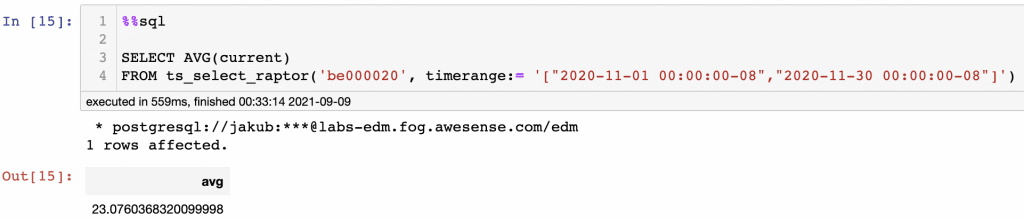
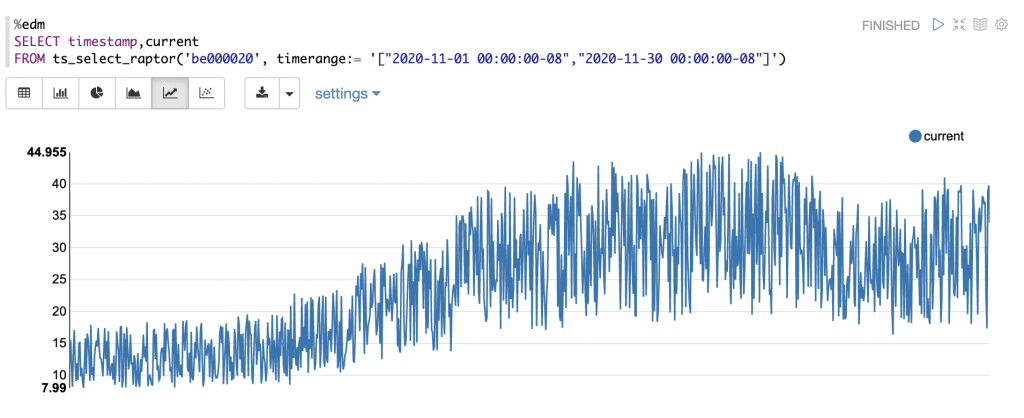
A more complex example is demonstrated next, where the example contains a query to quantify the average current (I) from the Awesense Raptor 3 sensor for November 2020.
A similar result can be achieved using the python modules psycopg2 and pandas. In the example below, psycopg2 is responsible for secure connection to Awesense Energy Data Model, and pandas are responsible for executing SQL query.
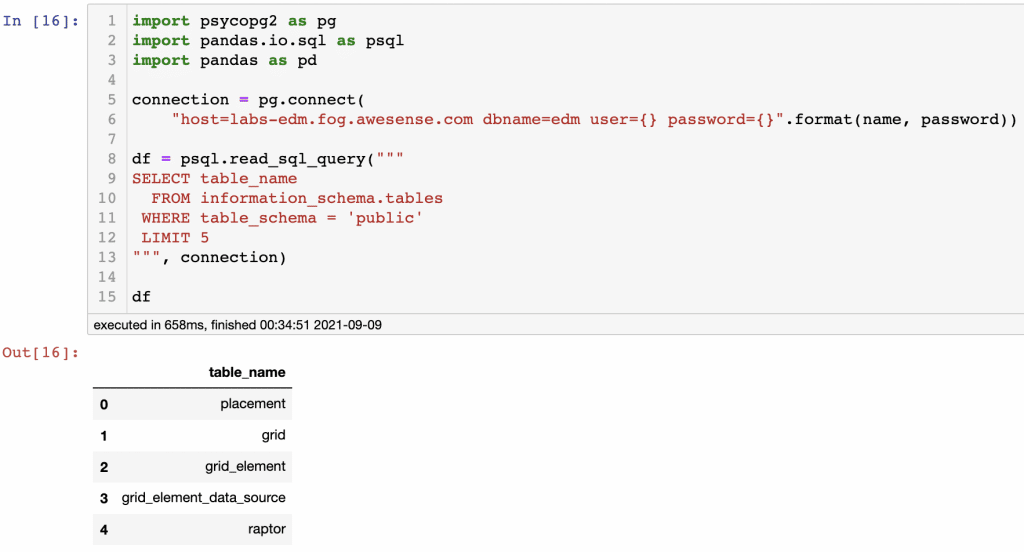
Similarly, an example with the average current on an Awesense Raptor can be achieved using psycopg2 & pandas.

Apache Zeppelin
To connect to the Awesense Platform from Apache Zeppelin, a new %jdbc group interpreter has to be created with the PostgreSQL driver.

Next, in the Zeppelin notebook, all that is needed is to call the %edm interpreter and to start directly interacting with the Awesense Energy Data Model.
To link to previous examples, let’s query Awesense Raptor 3 data using %edm interpreter. The query result is conveniently visualized in the same cell (which is a great feature of the Apache Zeppelin).
A Final Word
Data science notebook tools are a powerful way for you to build new applications and analytics focused on solving problems in your energy system. Often the most important step is asking the right questions. Today, with so much data being generated from electrical networks, very few questions can’t be answered through data. Data science notebooks offer a toolset for answering some of these complex questions, many of which we feared to even ask prior to their inception. If you’re having trouble solving a particular problem or need to visualize data in a new way – the Awesense Platform’s integrations with the data science notebook could be what you’re looking for.
Next Time, on the Awesense Build Better Series…
We hope you’ve enjoyed following this “Learn to Build Better” series, and we hope you continue to follow along. Stop living in the past with your old ways of tackling data. It’s time to use your data to propel you into the future, and we’re grateful that data science notebooks allow us to do just that.
Free For a Chat?
We love to connect with our wide audience and would love for you to share our content! Follow along with this series, and let us know what ideas you would like to see us write about. Let us know whether it’s more content about the topics we’ve already written on or even a specific use case or tool you would like to know more about. If you or your team are interested in building a custom application or use case using the Awesense Platform, or you have an analytical tool you would like us to demonstrate with our platform, please feel free to contact us or send an email to tools@awesense.com.
Resources
- https://medium.com/memory-leak/data-science-notebooks-a-primer-4af256c8f5c6
- https://towardsdatascience.com/how-to-pick-the-right-notebook-for-data-science-7dc418c4da57
- https://towardsdatascience.com/how-to-pick-the-right-notebook-for-data-science-7dc418c4da57